Binary data series analysis using Postgres window functions
Jan 6, 2020 · 9 minute read · Commentspostgressql
Few releases back, we introduced a new feature in Enectiva: analysis of binary data series. This feature allows our customers to make sense of data coming from sensors monitoring things like lights turned on by motion, gates and doors being open or anything that can be on/off, open/closed. The primary presentation of this data we were working towards looks like:
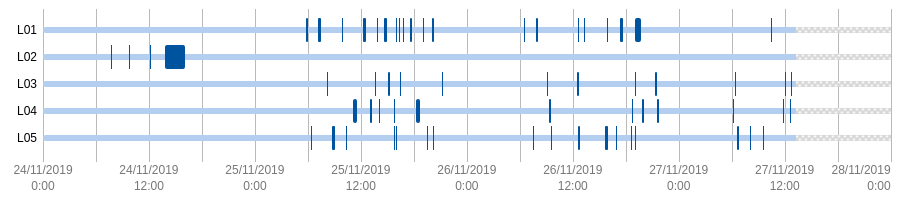
Each series has its line with intervals when the lights were turned on displayed as wider stripes in dark blue. I’d like to share the way we managed to obtain data for this presentation.
Source data
We’d already been monitoring several binary data series before we started working on this feature. The UI was very crude and hard to navigate but we had an ingestion pipeline resulting in data points in the form of time, value (float guaranteed to be either 0 or 1) and data_series_id. The values represented current state of a sensor at the given time. We received mostly values when the state changed, i.e. when the light was switched on or off, but there were also periodical checks in between to mitigate potential impact of a lost data point.
Sorted chronologically, we had a series of 1’s and 0’s for each sensor. The series could alternate between the two values but more likely there would be long stretches of 0’s followed by few 1’s and another series of 0’s and so on.
Goal
The goal was to show intervals when the light was on/the gate was open, i.e. when the sensor said 1. Since we should be getting the change events, we optimistically defined the start of an interval to be the time when 1 appears after 0 and an end of an interval to be when 0 appears after 1.
An intuitive algorithm is to iterate over chronologically sorted data points and whenever we encounter a change from 0 to 1 start tracking a new interval and end it when we get to another 0. This could be implemented but given the existing data, we knew that the ratio of intervals to the underlying data points was very small. The screenshot above illustrates this, there are around two dozen intervals over three a half days backed by hundreds of data points (that cannot be read from the screenshot) per series. Reading all data points would be wasteful so we decided to try to push the responsibility to the database.
Edge cases
Before I dive into the implementation, let’s consider the edge cases. We shouldn’t end up with any intervals when there are no data points, obviously. Similarly, we shouldn’t get any intervals if there’s only one data point. And we should have no intervals when all values within the range are 0’s.
An interval might straddle the boundaries of the inspected range - we’ll want to see it stretching right up to the edge of the range but we’ll omit anything outside the range. A more specific edge case is when all the data points in the range are 1’s - the interval should then cover the whole range.
We also want to distinguish no intervals from no data, i.e. all data points in teh range are 0s.
Implementation
The key trick to getting the data in the desired shape are window functions, combining several relations together by UNION and nesting, lots of nesting. Let’s start from the core and build the query out.
We know, we need to inspect all data points within a given range, sorted chronologically:
SELECT "time" AS "start_time",
"value"
FROM "data_series_data_points"
WHERE data_series_id = 2
AND ("time" BETWEEN '2019-09-24 22:00:00' AND '2019-09-26 22:00:00')
ORDER BY "time" ASC
We need to convert a series of data points into a series of intervals but that requires a stepping stone. We can’t go from two ovals to an owl. The intermediate step is to mark data points which are the first in a series of 1’s or 0’s.
SELECT "start_time"
, "value"
, lag("value", 1, 'infinity'::float) OVER (ORDER BY "start_time" ASC) != "value" AS "first_in_interval"
FROM (
-- the previous query here
) AS data_points_within_range
We keep the two columns start_time and value and a boolean column called first_in_interval. To get it, we compare the value of the current data point "value" with the value of the preceding data point lag("value", 1, 'infinity'::float) OVER (ORDER BY "start_time" ASC).
Let’s deconstruct this. OVER (ORDER BY "start_time" ASC) says that we want to use a window function, i.e. lag over the sorted chronologically relation (we have one window spanning the whole relation because we didn’t use PARTITION BY). lag("value" says we care about the value from the preceding row within the window. Only the first argument of lag is required, the second one is the distance of the compared row, default is one - meaning we want to compare the current row with its immediate neighbor. Because we want to provide a fallback value, 'infinity'::float, we have to explicitly pass the second argument as well. The fallback value is used when there is no preceding row, i.e. for the very first record in the relation. If unspecified, Postgres uses NULL which works but leads to a NULL:float comparison so why not make everything the same type.
Alright, so we have a list of data points labelled with a boolean flag first_in_interval. To extract intervals, we don’t care about data points in their middle, so let’s get rid of them:
SELECT *
FROM (
-- previous nested queries here
) AS tagged_data_points
WHERE "first_in_interval"
Right now, we have a list of data points which start an interval, we know what is the value in that interval but we don’t know when the interval ends. How about using a window function to find out? As long as we have data points at beginnings of intervals with both 1’s and 0’s, we can say that the beginning of one interval is the end of the other.
SELECT *,
lead("start_time") OVER () AS "end_time"
FROM (
-- previous nested queries here
) AS intervals
lead is a polar opposite of lag - end_time is the start_time of the row behind the current one. Since we don’t provide a fallback value, we don’t need to specify the second argument either.
This gets us pretty close to our goal but there are still several edge cases. Most notably, we don’t deal with the intervals straddling the edge of the range. To take them into account, we need to peak outside the range and get the closest data points on either side. The very first query is turned into:
(SELECT "time" AS "start_time",
"value"
FROM "data_series_data_points"
WHERE data_series_id = 2
AND ("time" < '2019-09-24 22:00:00')
ORDER BY "time" DESC
LIMIT 1)
UNION ALL
(SELECT "time" AS "start_time",
"value"
FROM "data_series_data_points"
WHERE data_series_id = 2
AND ("time" BETWEEN '2019-09-24 22:00:00' AND '2019-09-26 22:00:00')
ORDER BY "time" ASC)
UNION ALL
(SELECT "time" AS "start_time",
"value"
FROM "data_series_data_points"
WHERE data_series_id = 2
AND ("time" > '2019-09-26 22:00:00')
ORDER BY "time" ASC
LIMIT 1)
We get the data point closest to the range but still outside and the first data point after the range. Because we care about the same columns with the same data types, we can join the three relations together. Because we know there will be no duplicates, we use faster UNION ALL instead of plain UNION.
By adding the two data points (if they exist) we solved some very special edge cases - when the value of the series flips right before/after the inspected range. If it continued with 1s or 0s it would be no help in this form. However, we’ve already decided that we will trim intervals to the inspected range. We can mark the edge data points as such and treat them as if they were first in interval. One way to do it is to expand the second query to:
SELECT "start_time"
, "value"
, lag("value", 1, 'infinity'::float) OVER (ORDER BY "start_time" ASC) != "value" AS "first_in_interval"
, (
lag("value", 1) OVER (ORDER BY "start_time" ASC) IS NULL
OR
lead("value", 1) OVER (ORDER BY "start_time" ASC) IS NULL
) AS "is_at_the_edge"
FROM (
-- the previous query with UNION ALL's here
) AS data_points_within_and_around_range
We check if the previous and following row has any value and rely on the fact that lag and lead return NULL if there is no row.
With this second flag, we can add the boundary data points to a list of interval beginnings in the third level query:
SELECT *
FROM (
-- previous nested queries here
) AS tagged_data_points
WHERE ("first_in_interval" OR "is_at_the_edge")
If we run the complete query and there are some data points in the range, the last interval will always have NULL as the end_time. It either starts outside of the range (and we didn’t look further) or it’s based on the very last data point we have. We decided to not speculate and we don’t display such an interval by adding another filter on top of the query.
And that’s it. The complete query looks like:
SELECT *
FROM (SELECT *, lead("start_time") OVER () AS "end_time"
FROM (SELECT *
FROM (SELECT "start_time"
, "value"
, lag("value", 1, 'infinity'::float) OVER () != "value" AS "first_in_interval"
, (
lag("value", 1) OVER () IS NULL
OR
lead("value", 1) OVER () IS NULL
) AS "is_at_the_edge"
FROM (
(SELECT "time" AS "start_time",
"data_series_data_points"."value"
FROM "data_series_data_points"
WHERE "data_series_data_points"."data_series_id" = 2
AND ("time" < '2019-09-24 22:00:00')
ORDER BY "data_series_data_points"."time" DESC
LIMIT 1)
UNION ALL
(SELECT "time" AS "start_time",
"data_series_data_points"."value"
FROM "data_series_data_points"
WHERE "data_series_data_points"."data_series_id" = 2
AND ("time" BETWEEN '2019-09-24 22:00:00' AND '2019-09-26 22:00:00')
ORDER BY "data_series_data_points"."time" ASC)
UNION ALL
(SELECT "time" AS "start_time",
"data_series_data_points"."value"
FROM "data_series_data_points"
WHERE "data_series_data_points"."data_series_id" = 2
AND ("time" > '2019-09-26 22:00:00')
ORDER BY "data_series_data_points"."time" ASC
LIMIT 1)
) AS data_points_within_and_around_range
) AS tagged_data_points
WHERE ("first_in_interval" OR "is_at_the_edge")
) AS boundary_data_points
) AS intervals
WHERE "end_time" IS NOT NULL
This query returns all intervals with both of 1 and 0 as the value which intersect with the range. You might think of adding AND "value" = 1 to fetch only the intervals with the interesting value. We don’t do it because if the value is 0 over the whole range we get one 0 interval from the database, it allows the application code to distinguish it from the scenario when there’s no data at all.
Compared to the gradual steps, all the OVER clauses are empty. We can afford this (and avoid sorting) because the inner-most SELECT returns the data already in the correct order.
You might think that there’s too much nesting. From the core out:
- The first
SELECTfetches the data points - The second one tags the data points at the beginnings of intervals or at the edge of the range
- The third throws away the data points in the middles of intervals
- The fourth adds
end_times - And the fifth throws away the last one
The second and third steps seem like they could be collapsed but not really. Window functions cannot appear in WHERE clauses. So we have to keep the fourth & fifth combination as well.
The resulting query performs very well despite its apparent complexity. The performance is great with reasonable time ranges (up to a fortnight) and acceptable with longer ranges. We’re excited SQL allows us to express the query with window functions building on the raw data points without any special cache mechanism involved.
We're looking for developers to help us save energy
If you're interested in what we do and you would like to help us save energy, drop us a line at jobs@enectiva.cz.